ShopDreamUp AI ArtDreamUp
Deviation Actions









Suggested Deviants



Suggested Collections


















You Might Like…


















Featured in Groups




Description
Contents
Specs
- LaTeX distribution: TeXLive
- documentclass:
article - packages:
CJKutf8,pstricks,pst-xkey,pst-asr - fonts: Myoungjo/
Umj, Computer Modern Roman/cmr(Type1) - charset encoding: UTF-8
- compilation scheme:
latex && dvips && ps2pdf
[ ^ ] [ Contents ]
What’s this all about …
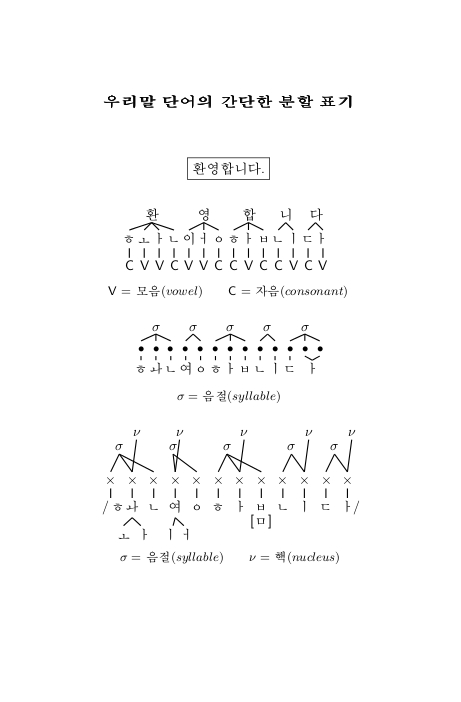
These are simple exercises about segmentation trees regarding phonology (음운론 音韻論) as a subdomain of theoretical linguistics, actually treating aspects about the organization of the sounds in the Korean language. And so is the header: “우리말 단어의 간단한 분할 표기” urimal daneoui gandanhan bunhal pyogi, lit. “Segmentational Representations of Our Language’s Words.” This is appropriated by the word “환영합니다.” (hwan|yeong|ham|ni|da. “Welcome!”).
The top is a distribution of vowels (V) and consonants (C), from syllable over jamo (1:many connections) to label tier (1:1 connection). Diphthong jamo are split into monophthongs, possibly combined with the initial zero-consonant /ㅇ-/, if a syllable has no onset.
Syllables in Korean words usually have got equal stressing, so this is not a distinctive or suprasegmental feature; other than in German, see e. g. the minimal pair “übersetzen” (to cross over) vs. “übersetzen” (to translate). The case is different for clauses and sentences. So in the middle example, where the beat units per consonants and vowels (including diphthongs) are marked by bullets, the ending vowelㅏ /a/ is bit more stressed and lasts double (while the voice goes down). This is implied by the connection to 2 beat nodes.
The bottom diagram is a combination of the former both, with a beat and a syllable tier, that explicitly points out the syllables’ nuclei. The Hangul phonemes set between slashes / ... /, and diphthongs are again split into its basic components (phones) to a tier below. Note the /ㅂ – b/: Due to assimilation with the following /ㄴ – n/, it is in fact spoken [ㅁ – m] and thus set between square brackets.
[ ^ ] [ Contents ]
TeXnical concerns
Drawing linguistic structures are easily be done for LaTeX with the cooperation of pstricks, pst-xkey, and other packages, which make use of PostScript instruction sets, quite popular in the printing industry. This takes effect on the compilation of
.tex source files however, as neither pdflatex, dvipdfm(x) or loading pst-pdf work. But no problem, that’s to be done with the traditional “LaTeX rule of three” then. – Anyway, always remember: The segmentation is done manually, LaTeX only provides the document preparation. The proper use of the linguistic packages require at least a basic understanding of their own syntax. The high quality typographic results justify this reasonable effort for the self-study though.pst-asr is perfect for creating speech segmentation diagrams. The shown examples are variations from simpler ones in the package’s documentation files. Be assured, there are no limits to complexity and to marking additional phonetic distinctive features like voicing, place of articulation, constituents of any kind and many more! – The following explanations are a rough summary. For an easier getting through, the
.tex-file given in the reference should also be opened in a browser or an editor.Each of the three figures are put in an
⧵asr ... ⧵endasr environment. Though they got different options for displaying node types, characters and their spacings, they share the same model of subdividing node elements to super- or sub-levels (tiers), and connecting them with lines. Elementary tiers are syl for syllables, tsfor timing slot (or: beats), and ph for phonemes, others can be defined. If nodes are initiated by ⧵@ and separated by |. They got arguments for the tier category, the starting and ending nodes with their numbered positions, and text strings as objects, like phonemes or labels; geulja (any kind of Korean characters) in the nodes must be protected by {}. Labels are mostly sound types (consonants, vowels) or syllable components (syllable, onset, nucleus, coda; often named in Greek letters). Arguments and options are set in different kinds of brackets. An example segmentation could be as easy as this one-liner for the middle diagram:⧵asr[tssym=⧵small{$bullet$}]⧵3{ㅎ}{ㅘ}{ㄴ}⧵2{여}{ㅇ}⧵3{ㅎ}{ ㅏ }{ㅂ}⧵2{ㄴ}{ㅣ ⧵,}⧵3{ㄷ}{ㅏ ⧵,}⧵endasrIt is clear, the
⧵ plus a number usually initiates the same number of arguments set between {} to create a single line connection to a tier; if there are less, it makes multiple connections. The time slot symbol is a small bullet. – On the other hand, for creating advanced figures, the increasing number of variables and its derivatives demands a certain amount of planning, as this excerpt of code from the bottom segmentation demonstrates:...
⧵newtier{diph} % definition of the tier level "diph" for assigning diphthongs components
...
⧵asr[...]|⧵varsyl{⧵syloffA}{0,1,2}|{ /⧵,ㅎ}{ㅘ}{ㄴ} ... % make nodes at the positions 0, 1, and 2 with the (printed) contents "/ ㅎ", "ㅘ", and "ㄴ"
⧵@[diphoffA](.8,diph){ㅗ}-(1,ph) % at node #1, make a tier node "A" starting from the diphthong (ㅘ) to phone level, named "ㅗ"
⧵@[diphoffB](1.2,diph){ㅏ}-(1,ph) % " "B" " , named "ㅏ"
...
⧵endasr[ ^ ] [ Contents ]
Links and References
- TeX related
- github resource: [link]
- CTAN entry for pst-asr: [link]
- official homepage of the CJK package (contains CJKutf8): [link]
- introducing other ways for linguistic LaTeX representations: [link]
- Further reading
- introduction to phonology at the SIL International: [link]
- resources for elementary phonology and psycholinguistics: [link] (EN)
- Wikipedia category catalogue for “Linguistics”: [link]
- Wikipedia category catalogue for “Natural language processing”: [link]
- Homepage of Praat, an Open Source multi-platform program for natural language processing, especially phonetics and segmentation: [link] – a great tool for providing and working on phonological data such as images, not so difficult to learn; I’d use it (again) for eventual later projects for documenting self-shot spectrograms then.
- “Linguistic Society of Korea” 한국언어학회: [link] (KO)
- Homepage of the “Phonology-Morphology Circle of Korea” 한국음운론학회: [link] (KO)
[ ^ ] [ Contents ]
.: ⟨ previous deviation :: { Typodrome | DTP } :: next deviation ⟩ :.
Comments welcome!
Image size
461x702px 48.39 KB
Comments1
Join the community to add your comment. Already a deviant? Log In
To much for me bro... haha